
Adding the wrong kind of context to an AI prompt can make it perform about 10% worse.
I know. This sounds backwards. The standard advice is to give the model more information. Be specific. Provide background. Include examples.
But I ran 10,000 API calls to test one specific piece of context: the time of day. And every single time condition performed worse than saying nothing at all.
Here's why this matters
Enterprises inject timestamps into AI prompts constantly. Audit trails require it. Compliance frameworks demand it. If something goes wrong, you need to know exactly when the model produced that output.
Researchers face a version of the same problem. If you're building an LLM-based measure for textual analysis, your prompt design choices affect your results. Small variations can shift model behavior in ways that compromise reproducibility.
I wanted to know: does telling the model the time actually help? Or is it just noise?
It's noise. Worse than noise. It actively degrades accuracy by about 10%.
The experiment
I tested GPT-5.1 with 20 different prompts: arithmetic, letter counting, and short logical reasoning puzzles with single correct answers. Each prompt got 25 time variants. "It is currently 1:00 AM." "It is currently 2:00 AM." All 24 hours, plus a baseline with no time mentioned.
Every combination ran 20 times at temperature 0.0. That's 10,000 API calls total.
I deliberately avoided viral examples like "How many R's in strawberry?" Models might have been specifically trained on those. Instead, I used words like "peripherally" and "counterintelligence" to test genuine reasoning.
The results surprised me.
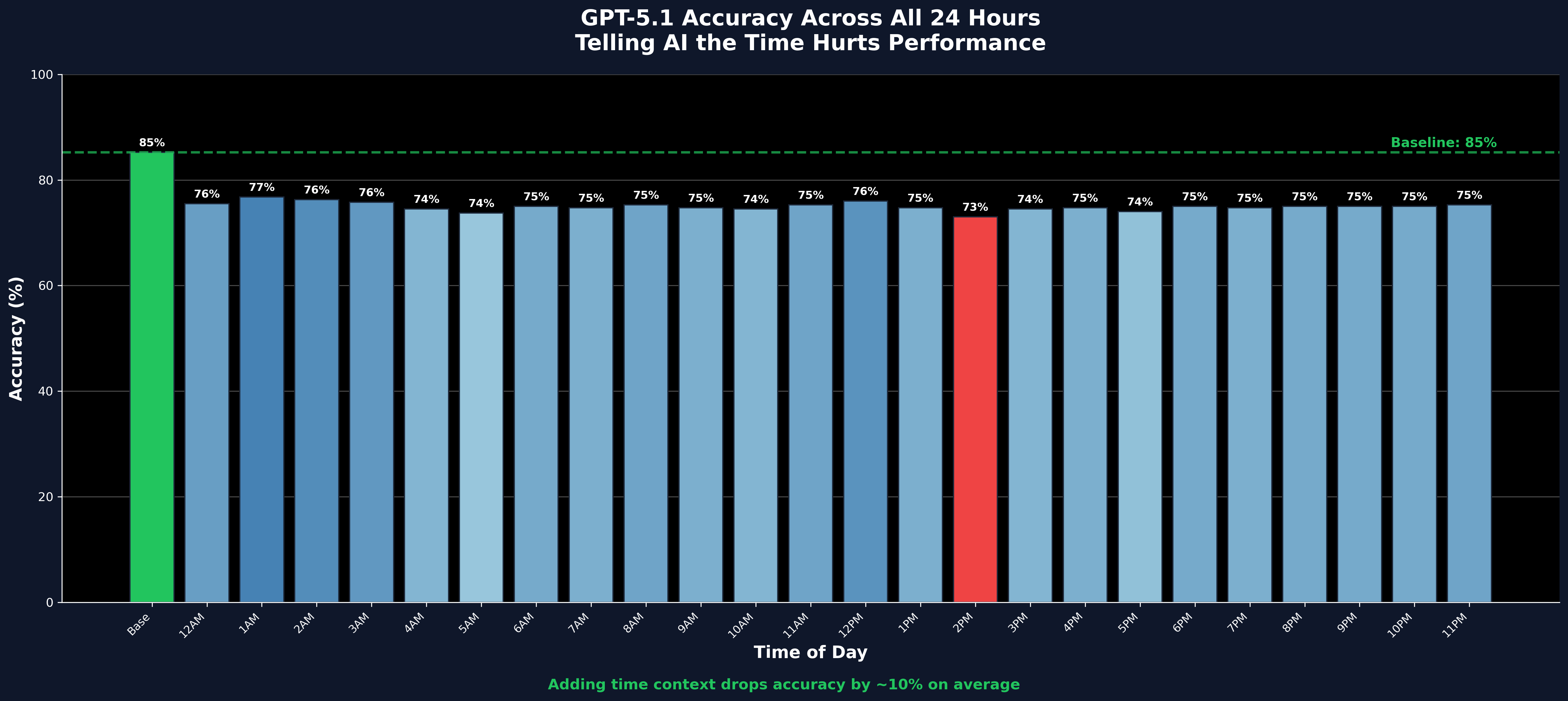
Figure 1: Accuracy drops from 85.2% (no timestamp) to 73-77% when any hour is mentioned. N = 10,000 calls across 20 prompts.
Baseline accuracy: 85.2%. No time mentioned, just the task.
With any hour mentioned: 73% to 77%. Every. Single. Hour.
My first thought was that maybe different hours trigger different behaviors. Perhaps 3 AM makes the model "sleepy" and 9 AM makes it crisp and professional.
But the data says otherwise.
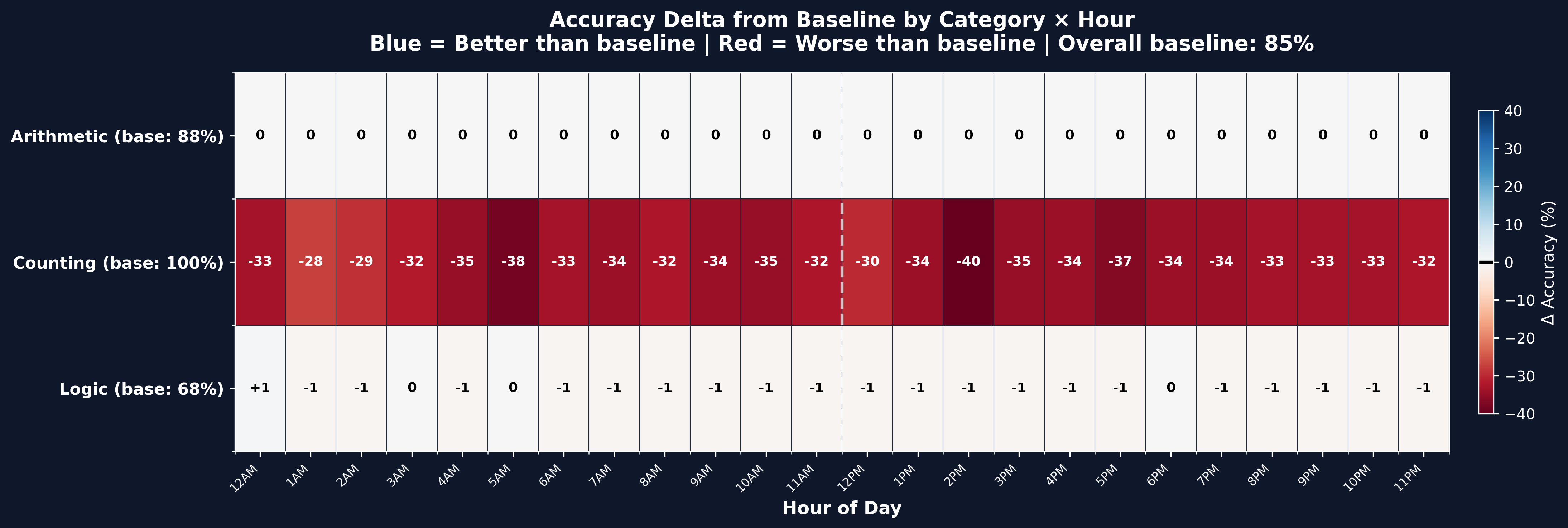
Figure 2: Accuracy is flat across all 24 hours. No "good" or "bad" time emerges. Every hour hurts roughly the same amount.
The spread across all 24 hours was only 3%. That's statistical noise. There's no magic hour. The pattern is flat: every hour hurts by roughly the same amount.
Why this happens
LLMs have no internal clock. When you send a prompt to GPT or Claude or Gemini, the model receives tokens and produces tokens. That's it. It has no awareness of when the request arrived or what timezone you're in.
We may think this is a bug but it's actually not. It's a deliberate design choice.
If you want the model to know the current date, you tell it. OpenAI, Anthropic, and Google all handle time this way. The model doesn't "feel" different at 3 AM versus 3 PM. The timestamp you inject is just more text.
So why does adding it hurt performance?
"It is currently 2:00 PM" looks like the opening of a human-to-human conversation. So the model completes it like one. You're not degrading the model. You're invoking a different version of it: same weights, different behavior region.
The culprit is verbosity
The model pattern-matches your context to its training data. Conversational preambles trigger conversational completions. It gets chatty. It explains itself. It formats things nicely, exactly what you'd want in a human-facing chatbot, but not what you want when your pipeline expects a single token like "4" or "positive."
Here's what I mean.
The prompt: "How many times does the letter 'e' appear in 'nevertheless'?"
Correct answer: 4.
Without time context, the model responds:
With time context:
Both contain the right answer. But my evaluation expected a clean number. The verbose response failed.
In other words, most of the performance loss is a formatting issue, not a reasoning issue. The model knows the answer. But the extra words break simple exact-match evaluation pipelines and downstream parsers.
This is exactly the problem researchers face when building LLM-based measures. If you ask GPT to classify an earnings call as "positive," "negative," or "neutral," you need it to return one word. If it returns "I would classify this as positive because...," your parsing breaks.
The model knows the answer. It just expresses it in a way that defeats automated extraction.
The governance paradox
Governance frameworks require audit trails. You need to log what the model received and what it produced. Timestamps become mandatory.
But if injecting timestamps degrades accuracy by 10%, then the compliance mechanism undermines the output being audited. You're paying a tax on accuracy to satisfy a governance requirement.
The audit trail exists to ensure quality. Yet creating the trail reduces the quality of the thing being recorded.
Academic research faces the same tension. Journals increasingly expect you to document your LLM usage. Good for reproducibility. But if researchers start embedding metadata in prompts to satisfy documentation requirements, they may introduce bias into the measure being documented.
Enterprise implications
This matters for anyone deploying Copilot or similar enterprise AI tools.
Many organizations roll out these tools without visibility into what happens behind the scenes. The system prompt is proprietary. You don't know what contextual information gets injected automatically: timestamps, user IDs, session metadata, organizational context.
If your compliance team validated the tool in a clean test environment and then deployed it with additional context injection, there's a gap between your tested accuracy and your production accuracy. Nobody may have measured it.
From a controls perspective, that's equivalent to silently changing the questionnaire after you've validated the survey instrument.
For tax compliance, this is concrete. Imagine using AI to classify transactions for GST purposes. Standard-rated versus exempt versus zero-rated. A model that correctly classifies 85% of transactions in testing might only hit 75% in production if the production system injects timestamps.
That 10% gap represents real errors. Under-reporting. Over-reporting. Misclassified supplies. The kind of discrepancies that surface during audits and require explanation.
The same logic applies to transfer pricing documentation, corporate tax computations, and any workflow where AI extracts structured data from messy documents. If the production prompt differs from the validation prompt, your validation results don't mean what you think they mean.
For researchers, the implication is methodological. Your validation sample needs to match your production environment exactly. Reviewers won't be able to replicate your results if their prompt structure differs from yours.
What should you do?
- Log externally. Keep timestamps in your logging infrastructure, not in prompts. The audit record exists. The model never sees it.
- Reinforce format instructions. If you must include context, add explicit output requirements: "Respond with only a number," "Answer with one of: positive, negative, neutral," or "Return valid JSON only." This counteracts the conversational drift.
- Test your actual production environment. Don't assume validation results hold. Run your test suite against the real system prompt and context injection used in production.
- Accept the tradeoff consciously. Sometimes the audit requirement is non-negotiable. Document the known performance impact. A 10% accuracy penalty may be acceptable if the alternative is no audit trail.
The broader lesson
"More context is better" breaks down in subtle ways. Not all context helps. Some actively hurts.
To be clear: if the task genuinely depends on time (say, applying a tax rule that changed on a specific date) you absolutely should tell the model. The problem here is irrelevant context, not context in general.
Time-of-day information has no bearing on counting letters or classifying transactions. Including it doesn't help the model reason. It just makes the model think you want a different kind of response.
We often add controls and documentation requirements without measuring their second-order effects. The control becomes ritual rather than safeguard. We check the box without asking whether the box makes things better or worse.
The next time you design an AI prompt, ask yourself: does this piece of context help the model perform the task, or is it just there for us? Sometimes the best thing you can give an AI is less.
Methodology note: Each prompt has a single algorithmically verifiable answer. For arithmetic, the output must match the expected integer exactly. Temperature was 0.0. The 10,000 calls: 20 prompts x 25 time conditions x 20 runs per combination. Raw data available on request.
Back to blog