
Users have long complained that GPT models seem to get worse over time. OpenAI has denied this. Who's right?
I designed 43 tests and ran them repeatedly over several months. The results are clear: model performance does drift over time, sometimes significantly.
The methodology
I created a battery of 43 standardized prompts covering seven categories: instruction following, arithmetic, letter counting, logical reasoning, code generation, factual recall, and multi-step tasks. Each test has an objectively correct answer. I ran these tests repeatedly across different GPT model versions.
This is not a perception study. It's measurement. Either the model gets the answer right or it doesn't.
What I found
The results form a clear U-shaped pattern:
| Model | Accuracy | Notes |
|---|---|---|
| GPT-4 (June 2023) | 86% | Original release |
| GPT-4-turbo | 46.5% | 40-point drop |
| GPT-4o variants | 63-70% | Partial recovery |
| GPT-5 (August 2025) | 86% | Full recovery |
| GPT-5.1 (November 2025) | 95.3% | New peak |
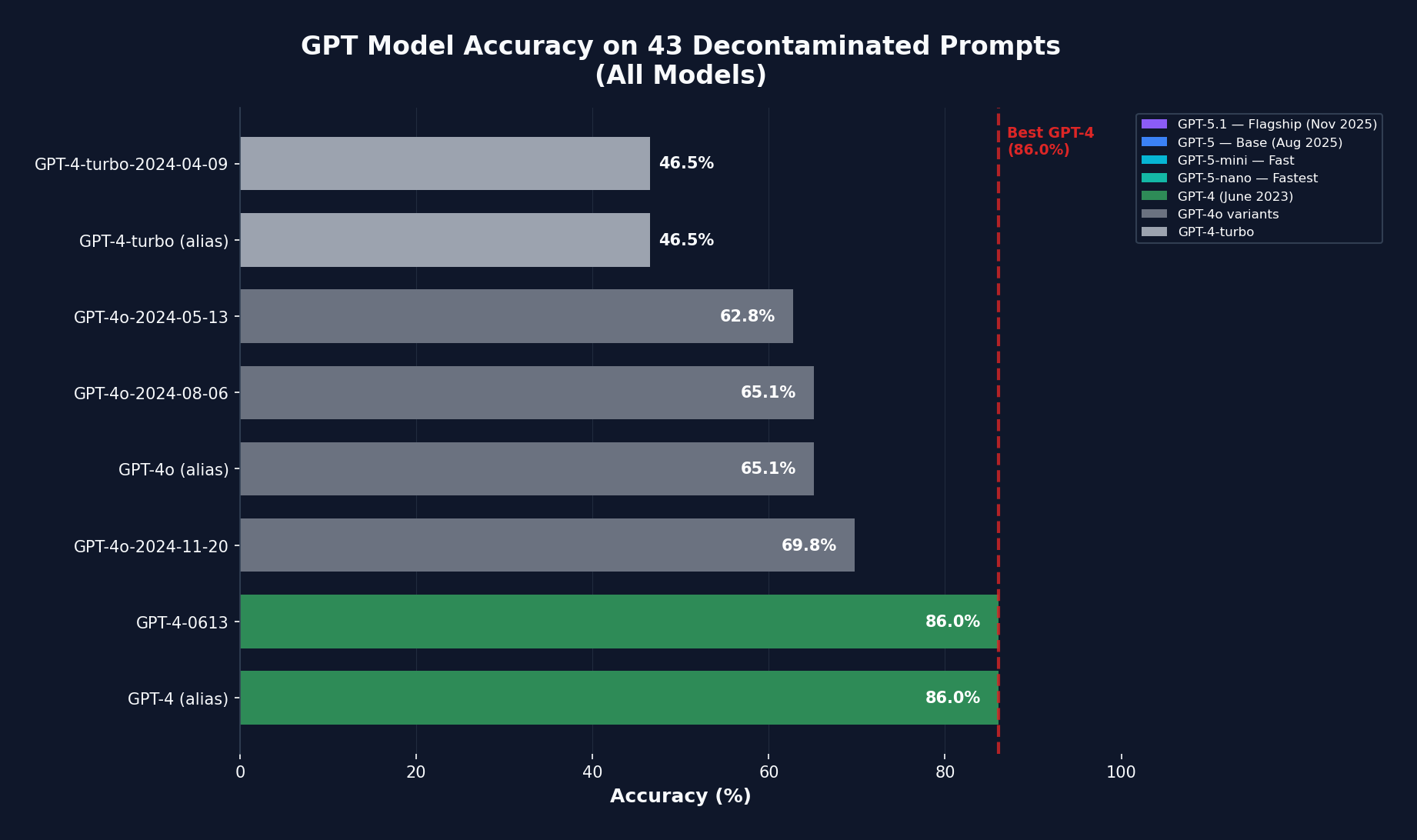
Accuracy across GPT model versions shows a distinct U-shaped pattern
The pattern is striking. Performance dropped dramatically with GPT-4-turbo, partially recovered with GPT-4o, and only returned to original levels with GPT-5.

The U-shaped recovery pattern when viewed chronologically
Why this happens
Several mechanisms could explain the degradation:
- Quantization: Reducing numerical precision in weights to save computation costs at the expense of subtle accuracy.
- Mixture of Experts (MoE): Architectural changes that route queries to specialized sub-networks, which may not always select the optimal expert for a given task.
- Aggressive safety fine-tuning: Post-training modifications to prevent harmful outputs can inadvertently degrade performance on benign tasks.
- Unannounced backend switching: The same model name may point to different underlying weights over time without user notification.
Critical insight: The regression is primarily in instruction following, not knowledge. The models often knew the correct answer but wrapped it in explanatory text when exact formatting was requested. This causes practical failures in structured output tasks.
When I asked models to "compute (999 minus 456) times 3 and respond with the integer only," GPT-4-turbo often provided correct math but returned something like "The answer is 1,629" instead of just "1629". The model knew the answer but failed the actual task.
The Pachinko problem
This reminds me of Japanese pachinko machines that offer early wins to hook players, then tighten odds. Cloud AI services change unpredictably while users remain unaware. You sign up for a capability, and that capability may silently shift.
The exact mechanism matters less than the implication: you cannot assume consistent performance from a model over time. What worked last month may not work this month.
Business implications
For regulated industries, this matters acutely:
- Financial reporting: Processes relying on consistent AI behavior face reliability questions when the underlying model changes undetected.
- Audit trails: Methodologies cannot be properly replicated if the AI producing outputs changes silently between periods.
- Tax compliance: Tax computations require stable model behavior for documentation purposes. IFRS, ISA, and tax standards expect reproducible processes.
- Transaction monitoring: AML and sanctions screening systems in financial institutions may degrade without notification, causing missed suspicious activity detection.
The governance gap is real: organizations documented processes using "GPT-4" without knowing that label might mean different things at different times.
What should you do?
- Pin specific model versions. Use API parameters to lock to exact model versions rather than aliases like "gpt-4" that may point to different underlying models over time.
- Build regression test suites. Implement automated testing for any production AI system. Track performance over time, not just at deployment.
- Require change notifications. If you're negotiating enterprise AI contracts, require vendors to notify you before model changes that could affect outputs.
- Document with version specificity. Record which exact model version produced which outputs for audit trails. "GPT-4" is not specific enough.
- Establish AI governance committees. Treat model risk like you would any other technology risk. Silent model changes should trigger review processes.
- Consider self-hosting. For stability-critical applications, open-source models that you control may provide more consistent behavior than cloud services that change without notice.
The bottom line
My data do not prove that OpenAI deliberately degraded their models. The changes may reflect safety improvements or architectural shifts rather than intentional cost-cutting.
But intent doesn't change the practical reality: if you built workflows assuming stable model behavior, those assumptions may be wrong. Teams using GenAI need continuous evaluation, not blind trust in a model label.
Key takeaway: Model capability is not static. The U-shaped recovery pattern suggests capabilities eventually improve, but the governance gap between what you validated and what runs in production remains unresolved. Monitor, don't assume.